ELK: GitOps
Mise en place d'un système de monitoring avec ELK en utilisant GitOps.
Nous allons voir dans cet article comment mettre en place un système de monitoring avec la stack ELK (Elasticsearch, Logstash, Kibana) en utilisant GitOps. GitOps est une méthode de gestion des configurations qui consiste à stocker l'ensemble des configurations de l'infrastructure dans un dépôt Git. Cela permet de garder un historique des modifications, de faciliter le déploiement et de garantir la cohérence des configurations.
Introduction
Ce document est une preuve de concept d'un ELK géré par git.
L'objectif est de démontrer de la faisabilité de la gestion d'un serveur ELK par git.
Note:
L'environnement de développement (VM) sera nommé indifféremment 'dev'; 'recette' ou 'pre prod' associé à la branche git
dev.L'environnement de production (VM) sera nommé indifféremment 'prod' ou 'production' associé à la branche git
main.
Prérequis et environnement de proof of concept
Serveurs
J'ai provisionné deux VMs :
- Une VM de dev (type recette ou pré-prod)
- Une VM de prod
Chaque VM à une configuration matérielle identique, soit 2 vCPU et 4GB de RAM.
D'un point de vue réseau, les VMs sont sur le même réseau privé et ont un accès à internet:
- VM de dev:
192.168.1.28/24 - VM de prod:
192.168.1.27/24
Structure du file system des VMs (simplifié):
.
├── prod/docker-elk
│ ├── docker-compose.yml
│ └── logstash
│ ├── config
│ │ ├── pipelines.yml
│ │ └── logstash.yml
│ ├── files -> ~/elk/logstash/outils/
│ └── pipeline
│ ├── index-meteo.conf
│ └── index-wine.conf
└── elk
Le dossier
elkest le dossier gitorigin/deven dev etorigin/mainen prod.
Installation des outils
Sur chaque VM, j'ai installé la suite ELK (Elasticsearch, Logstash, Kibana) entièrement dockerisée.
Via le projet GitHub docker-elk de deviantony.
Une modification a été apportée, via l'ajout d'un volume pour les fichiers de configuration de Logstash.
Fichier docker-compose.yml:
volumes:
- ./logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml:ro,Z
- ./logstash/pipeline:/usr/share/logstash/pipeline:ro,Z
- ./logstash/files:/usr/share/logstash/files
- ./logstash/config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro,Z
Serveur Git
Pour le serveur git, j'ai utilisé Github.
J'ai créé un repository privé.
Avec deux branches:
devpour la branche de développement, correspondant à la VM de devmainpour la branche de production, correspondant à la VM de prod
Structure du repository (dossier elk sur les VMs):
.
├── crontabs
│ └── crontab
├── dashboard
│ ├── meteo.ndjson
│ └── wine.ndjson
├── .git
│ └── ...
├── logstash
│ ├── conf.d
│ │ ├── index-meteo.conf
│ │ └── index-wine.conf
│ ├── outils
│ │ ├── meteo
│ │ │ ├── .gitignore
│ │ │ └── script.py
│ │ └── wine
│ │ ├── .gitignore
│ │ └── script.py
│ └── pipelines.yml
├── README.md
└── utils
├── download_dashboard.py
├── import_dashboard.py
├── sync_dev.sh
└── sync_prod.sh
Données de tests
Pour les données de tests, j'ai utilisé des données via deux APIs publiques:
Création des Dashboards
Pour la création des dashboards, nous allons prendre les deux exemples suivants:
- Météo
- Vins
Météo
Scripts de récupération des données
L'API est:
https://api.open-meteo.com/v1/forecast?latitude=52.52&longitude=13.41¤t=temperature_2m.
Le script de récupération des données de la météo est le suivant:
elk/logstash/outils/meteo/script.py
Il crée un fichier data_log.csv avec les données de la météo dans le dossier elk/logstash/outils/meteo/.
Il y a également un .gitignore pour ignorer le fichier data_log.csv dans le git:
*.csv
Création du pipeline Logstash
Le pipeline Logstash pour la météo est le suivant:
elk/logstash/conf.d/index-meteo.conf
Et le fichier pipeline.yml pour le pipeline:
elk/logstash/pipelines.yml
Crontab
Un crontab est mis en place pour exécuter le script de récupération des données de la météo toutes les demi-heures:
elk/crontabs/crontab
*/30 * * * * cd ~/elk/logstash/outils/meteo && python3 script.py
Dashboard Kibana
Le dashboard Kibana à été crée via l'interface de Kibana sur le serveur de dev après avoir importé les configurations sur le serveur (point suivant):
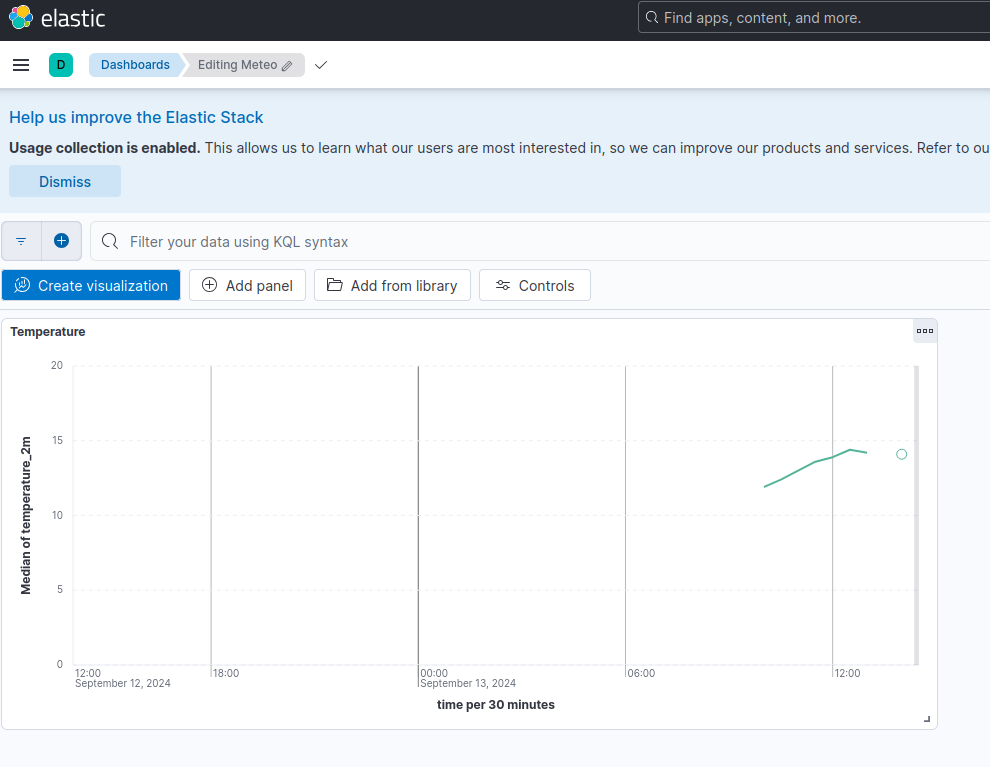
Il correspond juste à un graphique de la température actuelle.
Vins
Pour les vins, le processus est le même que pour la météo:
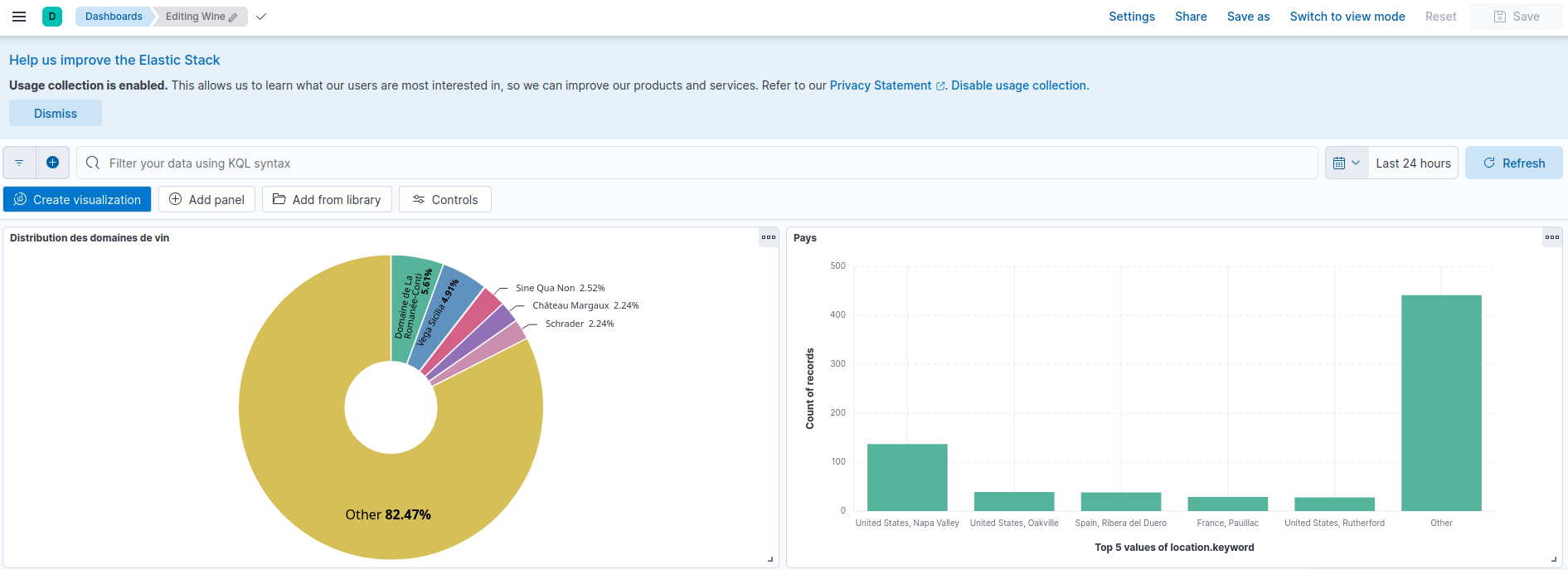
Synchronisation via Git
Actuellement les fichiers de configuration de Logstash et les scripts de récupération des données sont le serveur Git uniquement dans la branche dev.
Attention: les dashboards ci-dessus n'ont été crée qu'une fois les fichiers de configuration importés sur le serveur de dev.
Il faut donc déployer les modifications sur le serveur de dev dans un premier temps (pour la création des dashboards), puis sur le serveur de prod.
Scripts de synchronisation (WIP)
Pour cela j'ai créé des scripts de synchronisation:
sync_dev.shpour synchroniser les fichiers de la branchedevsur le serveur de devsync_prod.shpour synchroniser les fichiers de la branchemainsur le serveur de prod
Ces scripts ont été crée pour le proof of concept uniquement, et ne préfigure en aucun cas ceux définitifs qui seront utilisés dans un environnement de production.
Script sync_dev.sh
Le script fait:
- Copie des fichiers de configuration de Logstash du Git de la branche
devsur le serveur de dev. - Met à jour le crontab depuis le Git.
- Redémarre Logstash.
Script sync_prod.sh
Le script fait:
- Copie des fichiers de configuration de Logstash du Git de la branche
mainsur le serveur de prod. - Remplace les adresses IP dans les fichiers de configuration de Logstash pour correspondre à celles du serveur de prod.
- Importe les dashboards dans Kibana depuis le Git.
- Met à jour le crontab depuis le Git.
- Redémarre Logstash.
Exemple d'utilisation sur un dashboard
Création ou Modification
- Le développeur fait des modifications sur les fichiers de configuration de Logstash sur le serveur Git dans la branche
dev:- Configuration Logstash et Pipeline.
- Scripts de récupération des données.
- Crontab.
- Il commit les modifications et les pousse sur le serveur Git:
git checkout dev(Si le développeur n'est pas déjà dans la branche dev)git add [...]git commit -m "Ajout [...]"git push
- Sur le serveur de dev, il effectue la synchronisation :
cd ~/elkgit checkout dev(Si le serveur n'est pas déjà dans la branche dev)git pull./utils/sync_dev.sh
- Le serveur de dev est maintenant à jour, le développeur peut créer les dashboards sur Kibana.
- Télécharger les dashboards depuis Kibana:
cd ~/elkpython3 utils/download_dashboard.py [...]
- Pousser les dashboards sur le serveur Git:
git add dashboard/git commit -m "Ajout dashboard [...]"git push
Bravo, le nouveau dashboard est maintenant disponible sur le serveur de dev.
Passage en production
- Le développeur fusionne la branche
devdans la branchemainvia une PR. - Sur le serveur de prod, il effectue la synchronisation :
cd ~/elkgit pull./utils/sync_prod.sh
- Le serveur de prod est maintenant à jour.
CI
Pour automatiser les étapes de synchronisation, il faudra mettre en place une CI.
Nous pouvons utiliser GitHub Actions pour cela, ainsi que ssh-action pour exécuter des commandes sur les serveurs.
name: Deploy
on:
push:
branches: [main, dev]
pull_request:
branches: [main, dev]
jobs:
deploy:
name: Deploy
runs-on: ubuntu-latest
env:
SCRIPT_NAME: ${{ github.ref == 'refs/heads/main' && 'prod' || github.ref == 'refs/heads/dev' && 'dev' }}
BRANCH_NAME: ${{ github.ref == 'refs/heads/main' && 'main' || github.ref == 'refs/heads/dev' && 'dev' }}
steps:
- name: executing remote ssh commands using password
uses: appleboy/ssh-action@v1.0.3
with:
host: ${{ secrets.HOST }}
username: ${{ secrets.USERNAME }}
password: ${{ secrets.PASSWORD }}
port: ${{ secrets.PORT }}
script: cd ~/elk && git checkout ${{ env.BRANCH_NAME }} && git pull && bash -s < ./utils/sync_${{ env.SCRIPT_NAME }}.sh
Schéma de fonctionnement
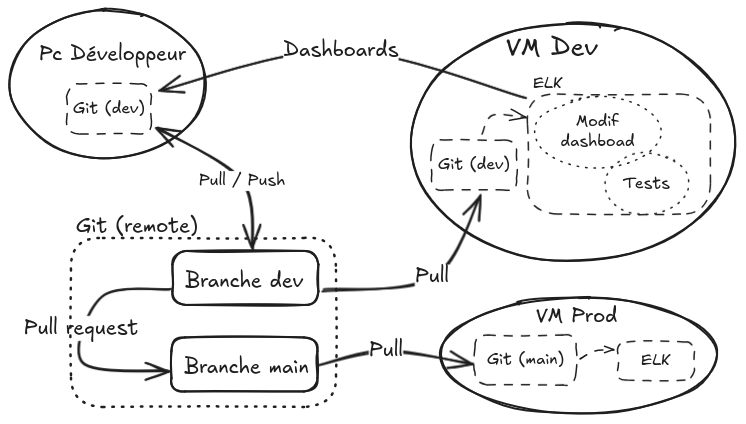
Explications
- Le dev push ses modifications locaux sur le serveur Git distant dans la branche
dev. - La VM de dev récupère les modifications via un
git pullsur le git local de la VM de dev. - Les fichiers de conf (hors dashboards) sont synchronisés sur la VM de dev.
- Le dev crée/modifie les dashboards sur Kibana.
- Le dev importe (via le script d'import) les dashboards sur son git local.
- Il push les dashboards sur le serveur Git.
- Le dev crée une PR pour merger la branche
devdans la branchemain. - La VM de prod récupère les modifications via un
git pullsur le git local de la VM de prod. - Les fichiers de conf (avec les dashboards) sont synchronisés sur la VM de prod.
Annexes
Scripts API Météo
import requests
import csv
import os
import time
# URL de l'API
API_URL = "https://api.open-meteo.com/v1/forecast?latitude=52.52&longitude=13.41¤t=temperature_2m"
# Nom du fichier CSV
CSV_FILE = 'data_log.csv'
# Fonction pour obtenir les données de l'API
def get_api_data():
try:
response = requests.get(API_URL)
if response.status_code == 200:
return response.json()
else:
print(f"Erreur lors de la requête API: {response.status_code}")
return None
except Exception as e:
print(f"Erreur lors de la connexion à l'API: {e}")
return None
# Fonction pour lire les dernières données du CSV
def get_last_data_from_csv():
if not os.path.exists(CSV_FILE):
return None
with open(CSV_FILE, mode='r') as file:
reader = csv.DictReader(file)
rows = list(reader)
if rows:
return rows[-1] # Dernière ligne
return None
# Fonction pour écrire les données dans le fichier CSV
def write_to_csv(data):
# Si le fichier n'existe pas, créez-le avec les en-têtes
file_exists = os.path.isfile(CSV_FILE)
with open(CSV_FILE, mode='a', newline='') as file:
writer = csv.DictWriter(file, fieldnames=data.keys())
if not file_exists:
writer.writeheader() # Écrire les en-têtes si fichier n'existe pas
writer.writerow(data)
print("Données ajoutées au fichier CSV.")
# Comparer les nouvelles données avec les anciennes
def data_has_changed(new_data, last_data):
# Comparez uniquement les éléments pertinents (par exemple, température)
if last_data is None:
return True
return float(new_data['current']['temperature_2m']) != float(last_data['temperature_2m'])
# Fonction principale
def main():
new_data = get_api_data()
if new_data:
# Extraire les informations utiles
data_to_log = {
"time": new_data['current']['time'],
"temperature_2m": new_data['current']['temperature_2m'],
"latitude": new_data['latitude'],
"longitude": new_data['longitude'],
"elevation": new_data['elevation']
}
# Lire les dernières données enregistrées
last_data = get_last_data_from_csv()
# Vérifier si les données ont changé
if data_has_changed(new_data, last_data):
write_to_csv(data_to_log)
else:
print("Les données n'ont pas changé.")
else:
print("Impossible d'obtenir les données de l'API.")
# Exécuter la fonction principale
if __name__ == "__main__":
main()
Configuration Logstash Météo
input {
file {
path => "/usr/share/logstash/files/meteo/data_log.csv"
start_position => "beginning"
sincedb_path => "/dev/null" # Pour relire le fichier depuis le début à chaque démarrage (utilisez un chemin persistant si nécessaire)
codec => plain { charset => "UTF-8" }
}
}
filter {
csv {
skip_header => true
separator => ","
columns => ["time", "temperature_2m", "latitude", "longitude", "elevation"]
}
# Convertir certains champs en types numériques pour Elasticsearch
mutate {
convert => {
"temperature_2m" => "float"
"latitude" => "float"
"longitude" => "float"
"elevation" => "float"
}
}
# Formater le champ "time" en format compatible ISO8601 pour Elasticsearch
date {
match => ["time", "ISO8601"]
target => "@timestamp"
}
}
output {
elasticsearch {
hosts => ["http://192.168.1.28:9200"] # Adresse de votre instance Elasticsearch
index => "meteo" # Nom de l'index où les données seront stockées
user => "elastic"
password => "changeme"
}
# Sortie console pour vérifier que tout fonctionne
stdout {
codec => rubydebug
}
}
Note: le chemin du fichier
pathest celui à l'intérieur du container docker Logstash, il correspond en réalité au fichierelk/logstash/outils/meteo/data_log.csvsur la VM.
Pipeline.yml
# This file is where you define your pipelines. You can define multiple.
# For more information on multiple pipelines, see the documentation:
# https://www.elastic.co/guide/en/logstash/current/multiple-pipelines.html
- pipeline.id: index-meteo
path.config: "/usr/share/logstash/pipeline/index-meteo.conf"
- pipeline.id: index-wine
path.config: "/usr/share/logstash/pipeline/index-wine.conf"
Note: le path est celui à l'intérieur du container docker Logstash, il correspond en réalité au dossier
elk/logstash/conf.d/sur la VM.
Script sync_dev.sh
#!/bin/bash
#Copy pipeline and conf
cp -r ~/elk/logstash/conf.d/* ~/prod/docker-elk/logstash/pipeline/
cp ~/elk/logstash/pipelines.yml ~/prod/docker-elk/logstash/config/pipelines.yml
#Update crontab file
crontab ~/elk/crontabs/crontab
# Restart logstash
cd ~/prod/docker-elk && docker compose restart logstash
#Only for testing in docker env
#ln -s ~/elk/logstash/outils/ ~/prod/docker-elk/logstash/files
Script sync_prod.sh
#!/bin/bash
#Copy pipeline and conf
cp -r ~/elk/logstash/conf.d/* ~/prod/docker-elk/logstash/pipeline/
cp ~/elk/logstash/pipelines.yml ~/prod/docker-elk/logstash/config/pipelines.yml
#Change IP addresses
REPERTOIRE="/home/elk/prod/docker-elk/logstash/pipeline"
ANCIENNE_IP="192.168.1.28"
NOUVELLE_IP="192.168.1.27"
# Check if the directory exists
if [ ! -d "$REPERTOIRE" ]; then
echo "Le répertoire $REPERTOIRE n'existe pas."
exit 1
fi
# Loop through all files in the directory
for fichier in "$REPERTOIRE"/*; do
if [ -f "$fichier" ]; then
sed -i "s/$ANCIENNE_IP/$NOUVELLE_IP/g" "$fichier"
echo "IP remplacée dans le fichier $fichier"
fi
done
#Import dashboards
cd ~/elk && python3 utils/import_dashboard.py all
# Update crontab
crontab ~/elk/crontabs/crontab
# Restart logstash
cd ~/prod/docker-elk && docker compose restart logstash
#Only for testing in docker env
#ln -s ~/elk/logstash/outils/ ~/prod/docker-elk/logstash/files
Script download_dashboard.py
"""
Script to download a Kibana dashboard as a NDJSON file.
"""
import base64
import sys
import os
import requests
# Constants configuration
KIBANA_HOST = "http://localhost:5601" # Replace with your Kibana host
SPACE_ID = "default" # Replace with your Kibana space ID if needed
EXPORT_PATH = "./dashboard" # Directory to store the backups
USERNAME = "elastic" # Replace with your Elasticsearch username
PASSWORD = "changeme" # Replace with your Elasticsearch password
def list_object(kibana_host: str, space_id: str, object_type: str) -> list:
"""
Retrieves a list of objects from Kibana.
Args:
kibana_host (str): The URL of the Kibana host.
space_id (str): The ID of the Kibana space.
object_type (str): The type of objects to retrieve.
Returns:
list: A list of saved objects retrieved from Kibana.
"""
url = f"{kibana_host}/s/{space_id}/api/saved_objects/_find?type={object_type}"
headers = {
"Authorization": f"Basic {base64.b64encode(f'{USERNAME}:{PASSWORD}'.encode()).decode()}",
"kbn-xsrf": "true",
"Content-Type": "application/json",
}
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
return response.json()["saved_objects"]
def fetch_object(
kibana_host: str, space_id: str, object_type: str, object_id: str
) -> bytes:
"""
Fetches an object from Kibana using the specified parameters.
Args:
kibana_host (str): The URL of the Kibana host.
space_id (str): The ID of the Kibana space.
object_type (str): The type of the object to fetch.
object_id (str): The ID of the object to fetch.
Returns:
bytes: The content of the fetched object.
Raises:
requests.exceptions.HTTPError: If the request to Kibana fails.
requests.exceptions.Timeout: If the request to Kibana times out.
"""
url = f"{kibana_host}/s/{space_id}/api/saved_objects/_export"
headers = {
"Authorization": f"Basic {base64.b64encode(f'{USERNAME}:{PASSWORD}'.encode()).decode()}",
"kbn-xsrf": "true",
"Content-Type": "application/json",
}
payload = {
"includeReferencesDeep": "true",
"objects": [{"type": object_type, "id": object_id}],
}
response = requests.post(url, headers=headers, json=payload, timeout=10)
response.raise_for_status()
return response.content
def save_raw_data(data: bytes, export_path: str, filename: str) -> str:
"""
Save raw data to a file.
Args:
data (bytes): The raw data to be saved.
export_path (str): The path where the file will be saved.
filename (str): The name of the file.
Returns:
str: The full path of the saved file.
Raises:
OSError: If there is an error creating the directory or writing the file.
"""
os.makedirs(export_path, exist_ok=True)
file_path = os.path.join(export_path, filename)
with open(file_path, "wb") as f:
f.write(data)
return file_path
def get_object_id(
kibana_host: str, space_id: str, object_type: str, name: str
) -> str | None:
"""
Retrieves the ID of a saved object in Kibana based on its type and name.
Args:
kibana_host (str): The URL of the Kibana host.
space_id (str): The ID of the Kibana space.
object_type (str): The type of the saved object.
name (str): The name of the saved object.
Returns:
str: The ID of the saved object if it exists, None otherwise.
Raises:
requests.exceptions.RequestException: If an error occurs while making the request.
"""
url = f"{kibana_host}/s/{space_id}/api/saved_objects/_find?type={object_type}&search_fields=title&search={name}"
headers = {
"Authorization": f"Basic {base64.b64encode(f'{USERNAME}:{PASSWORD}'.encode()).decode()}",
"kbn-xsrf": "true",
"Content-Type": "application/json",
"Accept": "application/json",
}
response = requests.get(url, headers=headers, timeout=10)
# Check if the object exists (save_objects = 1)
if response.json()["total"] != 1:
return None
response.raise_for_status()
return response.json()["saved_objects"][0]["id"]
def main():
"""
Downloads a dashboard from Kibana.
Usage: python download_dashboard.py <dashboard_name>
To download all dashboards, use 'all' as argument.
"""
# Check arguments (=1)
if len(sys.argv) != 2:
print(
"Usage: python download_dashboard.py <dashboard_name> \n To download all dashboards, use 'all' as argument"
)
sys.exit(1)
# Get the dashboard name
dashboard_name = sys.argv[1]
# Get the object type
object_type = "dashboard"
# Get the object ID
if dashboard_name == "all":
objects = list_object(KIBANA_HOST, SPACE_ID, object_type)
for obj in objects:
obj_id = obj["id"]
obj_name = obj["attributes"]["title"]
obj_type = obj["type"]
print(f"Downloading {obj_name}...")
data = fetch_object(KIBANA_HOST, SPACE_ID, obj_type, obj_id)
save_raw_data(data, EXPORT_PATH, f"{obj_name}.ndjson")
else:
obj_id = get_object_id(KIBANA_HOST, SPACE_ID, object_type, dashboard_name)
# Check if the object exists
if not obj_id:
print(f"Dashboard {dashboard_name} not found")
sys.exit(1)
print(f"Downloading {dashboard_name}...")
data = fetch_object(KIBANA_HOST, SPACE_ID, object_type, obj_id)
save_raw_data(data, EXPORT_PATH, f"{dashboard_name}.ndjson")
if __name__ == "__main__":
main()
Script import_dashboard.py
"""
This script imports a Kibana dashboard from a file to a Kibana instance.
"""
import base64
import sys
import os
import requests
# Constants configuration
KIBANA_HOST = "http://localhost:5601" # Replace with your Kibana host
SPACE_ID = "default" # Replace with your Kibana space ID if needed
EXPORT_PATH = "./dashboard" # Directory to store the backups
USERNAME = "elastic" # Replace with your Elasticsearch username
PASSWORD = "changeme" # Replace with your Elasticsearch password
def load_raw_data(file_path: str) -> bytes:
"""
Load raw data from a file.
Args:
file_path (str): The path to the file.
Returns:
bytes: The content of the file as bytes.
"""
with open(file_path, "br") as f:
return f.read()
def list_ndjson_files(directory: str) -> list:
"""
List all NDJSON files in a directory.
Args:
directory (str): The directory path.
Returns:
list: A list of NDJSON files in the directory.
"""
return [f for f in os.listdir(directory) if f.endswith(".ndjson")]
def import_to_kibana(
kibana_host: str, space_id: str, data: bytes, import_type: str
) -> dict:
"""
Imports data to Kibana.
Args:
kibana_host (str): The URL of the Kibana host.
space_id (str): The ID of the Kibana space.
data (bytes): The data to be imported.
import_type (str): The type of import.
Returns:
dict: The JSON response from the import request.
Raises:
requests.HTTPError: If the import request fails.
"""
url = f"{kibana_host}/s/{space_id}/api/saved_objects/_import"
headers = {
"kbn-xsrf": "true",
"Authorization": f"Basic {base64.b64encode(f'{USERNAME}:{PASSWORD}'.encode()).decode()}",
}
files = {"file": (f"{import_type}.ndjson", data)}
response = requests.post(
url, headers=headers, files=files, params={"overwrite": "true"}, timeout=10
)
response.raise_for_status()
return response.json()
def main():
"""
Main function for importing a dashboard.
Usage: python import_dashboard.py <dashboard_name>
To import all dashboards in the directory, ussage: python import_dashboard.py all
Parameters:
- dashboard_name (str): The name of the dashboard to import.
Returns:
- None
Raises:
- SystemExit: If the number of command line arguments is not equal to 2.
- SystemExit: If the dashboard file does not exist.
- SystemExit: If there is an error importing the dashboard.
"""
# Check arguments (=1)
if len(sys.argv) != 2:
print("Usage: python import_dashboard.py <dashboard>")
sys.exit(1)
# Get the dashboard name
dashboard_name = sys.argv[1]
# Check if the dashboard is all
if dashboard_name == "all":
# Get all the dashboard files
dashboard_files = list_ndjson_files(EXPORT_PATH)
for dashboard_file in dashboard_files:
data = load_raw_data(os.path.join(EXPORT_PATH, dashboard_file))
# Import the dashboard
response = import_to_kibana(KIBANA_HOST, SPACE_ID, data, "dashboard")
# Print the response
if response.get("success", False):
print(f"Dashboard {dashboard_file} imported successfully")
else:
print(
f"Failed to import dashboard {dashboard_file}: {response.get('error', '')}"
)
sys.exit(1)
sys.exit(0)
else:
# Check if the dashboard file exists
if not os.path.exists(os.path.join(EXPORT_PATH, f"{dashboard_name}.ndjson")):
print(f"Dashboard {dashboard_name} not found")
sys.exit(1)
# Load the dashboard file
dashboard_file = os.path.join(EXPORT_PATH, f"{dashboard_name}.ndjson")
data = load_raw_data(dashboard_file)
# Import the dashboard
response = import_to_kibana(KIBANA_HOST, SPACE_ID, data, "dashboard")
# Print the response
if response.get("success", False):
print(f"Dashboard {dashboard_name} imported successfully")
else:
print(
f"Failed to import dashboard {dashboard_name}: {response.get('error', '')}"
)
sys.exit(1)
if __name__ == "__main__":
main()